Android 之 LruCache
Android 缓存机制—— LruCache
一、Android 中的缓存策略
一般来说,缓存策略主要包含添加、获取和删除这三类操作
二、LruCache 的使用
Android 3.1
近期最少使用算法
LinkedHashMap
使用:缓存大小、sizeOf()
1 | int maxMemory = (int)(Runtime.getRuntime().totalMemory() / 1024); |
三、实现原理
LinkedHashMap<key, value>
由此可见 LruCache中维护了一个集合LinkedHashMap,该 LinkedHashMap 是以访问顺序排序的。当调用put()方法时,就会在结合中添加元素,并调用trimToSize()判断缓存是否已满,如果满了就用 LinkedHashMap 的迭代器删除队尾元素,即近期最少访问的元素。当调用get()方法访问缓存对象时,就会调用 LinkedHashMap 的get()方法获得对应集合元素,同时会更新该元素到队头。
通过下面的构造函数来指定 LinkedHashMap 中双向链表的结构是访问顺序还是插入顺序。
1 | public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder){ |
1 | public static final void main(String[] args){ |
即最近访问的最后输出,那么这就正好满足 LRU 缓存算法的思想。
LruCache 源码:
构造函数
1 | public LruCache(int maxSize){ |
put()
1 | public put(K key, V value){ |
trimToSize()
判断缓存是否已满,如果满了就要删除近期最少使用的算法。
1 | public void trimToSize(int maxSize){ |
trimToSize()不断地删除 LinkedHashMap 中队尾的元素,即近期最少访问的,直到缓存大小小于最大值。
当调用 LruCache 的get()获取集合中的缓存对象时,就代表访问了一次该元素,将会更新队列,保持整个队列是按照访问顺序排序。这个更新过程就是在 LinkedHashMap 中的get()中完成的。
get()
1 | public final V get(K key){ |
LruCache 中维护了一个集合 LinkedHashMap,该 LinkedHashMap 是以访问顺序排序的。当调用put()方法时,就会在集合中添加元素,并调用trimToSize()判断缓存是否已满,如果满了就用 LinkedHashMap 的迭代器删除队首元素,即近期最少访问的元素。当调用get()方法访问缓存对象时,就会调用 LinkedHashMap 的get()方法获得对应集合元素,同时更新该元素到队尾。
四、LinkedHashMap 数据结构原理
初识
HashMap 的迭代顺讯并不是 HashMap 放置的顺序,也就是无序,在一些场景我们期待一个有序的 Map,这时候就可以用到 LinkedHashMap。它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap 保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者访问顺序。
| 关注点 | 结论 |
|---|---|
| LinkedHashMap 是否允许空 | Key 和 Value 都允许空 |
| LinkedHashMap 是否允许重复数据 | Key 重复会覆盖、Value 允许重复 |
| LinkedHashMap 是否有序 | 有序 |
| LinkedHashMap 是否线程安全 | 非线程安全 |
原理
LinkedHashMap 可以认为是 HashMap + LinkedList,即它使用 HashMap 操作数据结构,又使用 LinkedList 维护插入元素的先后顺序。
LinkedHashMap 的基本实现思想就是多态。
1 | public class LinkedHashMap<K, V> extends HashMap<K, V> implements Map<K, V>{ |
1 | private transient Entry<K, V> header; //双向链表的头结点 |
LinkedHashMap 提供了 5 个重载的构造方法,默认都采用插入顺序来维持取出键值对的次序。所有的构造方法都是通过调用父类的构造方法来创建对象的。
LinkedHashMap 和 HashMap 的区别在于他们的基本数据结构上,看一下 LinkedHashMap 的基本数据结构,也就是 Entry:
1 | private static class Entry<K, V> extends HashMap.Entry<K, V>{ |
| K key |
|---|
| V value |
| Entry<K, V> next |
| int hash |
| Entry<K, V> before |
| Entry<K, V> after |
next 是用于维护 HashMap 指定 table 位置上连接的 Entry 的顺序的;before、after 是用于维护 Entry 插入的先后顺序。
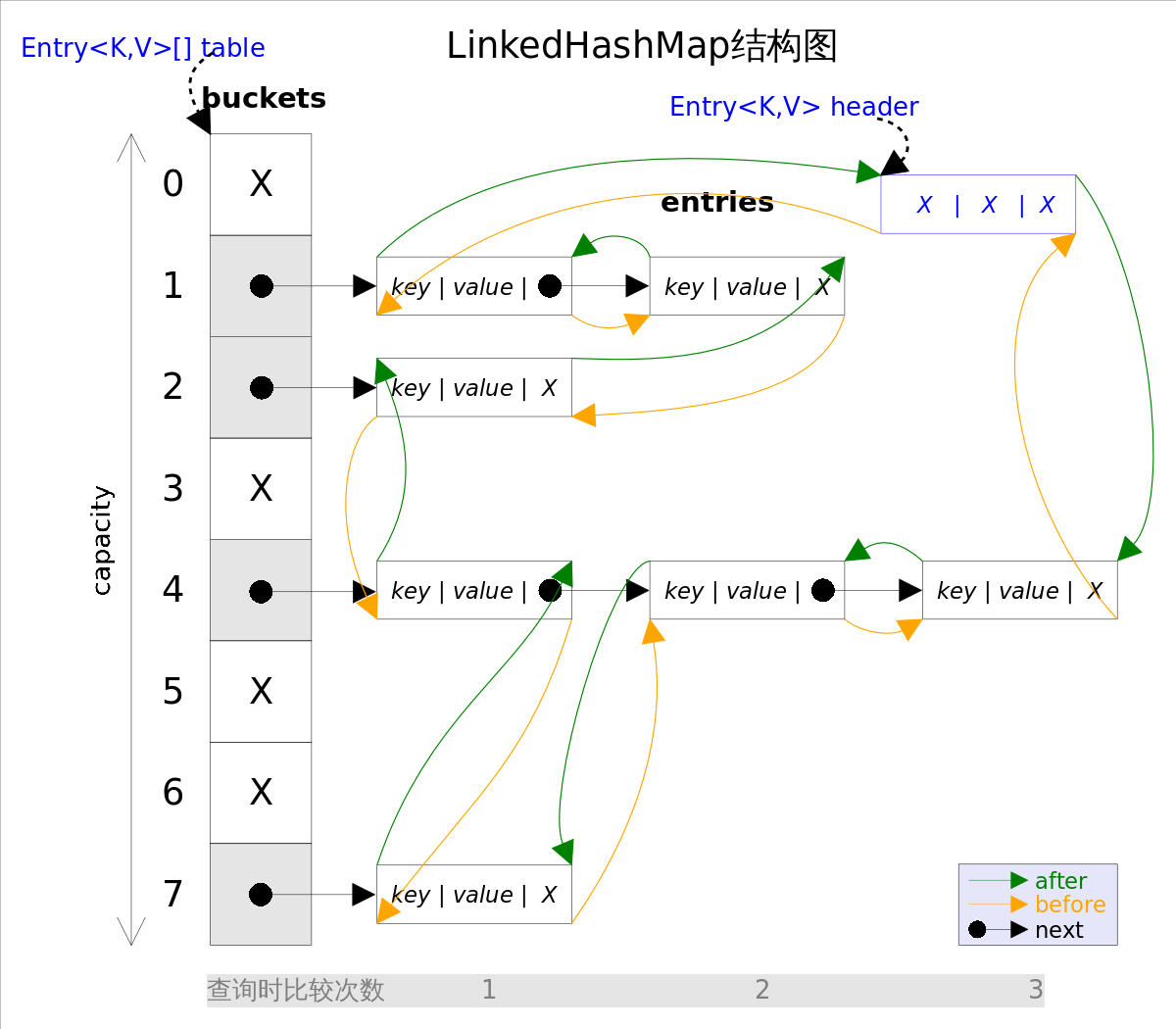
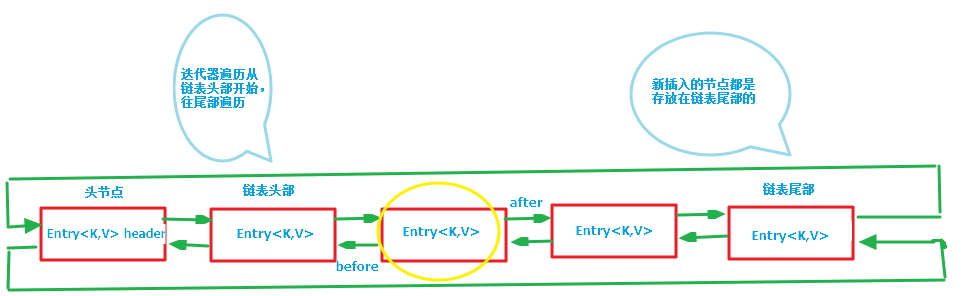
循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或是最近插入的节点,迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的 header 节点,该节点不存放 key-value 内容,为 LinkedHashMap 类的成员属性,循环双向链表的入口。
初始化 LinkedHashMap
1 | public static void main(String[] args){ |
1 | public LinkedHashMap(){ |
1 | public HashMap(){ |
这里出现了第一个多态:init()。尽管init()方法定义在 HashMap 中,但是由于:
- LinkedHashMap 重写了
init() - 实例化出来的是 LinkedHashMap
因此实际调用的init()是 LinkedHashMap 重写的init()。假设 header 的地址是0x00000000,那么初始化完毕,实际上是这样的:

header 不放在数组中,它的作用就是用来指示开始元素和标志结束元素的。header 的目的是为了记录第一个插入的元素是谁,在遍历的时候能够找到第一个元素。
LinkedHashMap 存储元素
LinkedHashMap 并未重写父类 HashMap 的put(),而是重写了父类 HashMap 的put()调用的子方法void recordAccess(HashMap m),void addEntry(int hash, K key, V value, int bucketIndex)和void createEntry(int hash, K key, V value, int bucketIndex),提供了自己特有的双向链表列表的实现。
1 | public V put(K key, V value){ |
1 | void addEntry(int hash, K key, V value, int bucketIndex){ |
1 | void createEntry(int hash, K key, V value, int bucketIndex){ |
1 | private void addBefore(Entry<K, V> existingEntry){ |
createEntry(int hash, K key, V value, int bucketIndex)覆盖了父类的方法。这个方法不会拓展 table 数组的大小。该方法首先保留 table 中 bucketIndex 处的节点,然后调用 Entry 的构造方法(将调用到父类 HashMap.Entry 的构造方法)添加一个节点,即当前节点的 next 引用指向 table[bucketIndex] 的节点,之后调用的e.addBefore(header)是修改链表,接 e 节点添加到 header 节点之前。
这里的插入有两重含义:
- 从 table 的角度看,新的 Entry 需要插入到对应的 bucket 里,当有哈希冲突时,采用头插法将新的 Entry 插入到冲突链表的头部。
- 从 header 的角度看,新的 Entry 需要插入到双向链表的尾部
总的来看,LinkedHashMap 的实现就是 HashMap + LinkedList 的实现方式,以 HashMap 维护数据结构,以 LinkedList 的方式维护数据的插入顺序
LinkedHashMap 读取元素
LinkedHashMap 重写了父类 HashMap 的get(),实际在调用父类getEntry()方法查找到元素后,再判断当排序模式accessOrder为true时(即按访问顺序排序),先将当前节点从链表中移除,然后再将当前节点插入到链表尾部。由于链表的增加、删除操作是常量级的,故并不会带来性能的损失。
1 | public V get(Object key){ |
1 | void recordAccess(HashMap<K, V> m){ |
1 | private void remove(){ |
1 | private void addBefore(Entry<K, V> existingEntry){ |